원본글: How to choose the number of topics / partitions in a Kafka Cluster?
How to choose the number of topics / partitions in a Kafka Cluster?
위 제목에 대한 질문은 Apache Kakfa 를 사용하는 사용자들이 궁금해하는 것 중에 하나이다. 이 포스트에서는 이 질문에 대한 답변을 위해 몇 가지 중요한 issue 및 벤치마크 테스트 결과에 다룬다.
먼저 한 가지 알아두어야 할 것은 Kafka가 메시지를 주고 받기 위해 사용하는 topic과 partition 단위는 Kafka가 메시징을 주고 받는데 병렬적으로 처리할 수 있는 단위 라는 것이다. Producer와 broker 사이드에서 메시지를 각 partition으로 보낼 때 이 것은 병렬적으로 처리된다. Kafka는 어느 특정 partition에 있는 메시지는 무조건 한 특정 consumer를 담당하는 스레드로 보내게 된다. 따라서 이 병렬 처리하는 정도는 partition의 개수에 따라 결정되는 것이다. 일반적으로 한 Kafka cluster에 partition의 개수가 많으면 많을수록 throughput은 증가할 것이다.
각 partition 마다 낼 수 있는 throughput은 어떻게 producer 및 consumer가 구현되었는지에 따라 다르다. Producer의 경우에는 메시지 압축 코덱이나, 일괄 처리되는 메시지 크기, replication의 정도 등일 수 있겠다. Consumer의 경우에는 얼마나 비즈니스 로직이 각 메시지를 빨리 처리하는가에 대해 달려 있다.
Partition의 개수를 원하는 만큼 늘리는 것이 가능하다지만, 만약 key와 같이 사용한다면 좀 더 신경써야할 부분이 있다. 만약 key와 메시지를 같이 보낼 경우, Kafka는 key 값을 해싱하여 나온 partition id로 메시지를 보낸다. 이 것은 같은 key 값을 가지는 메시지는 항상 같은 consumer에 의해 처리된다는 것을 보장한다. (항상 같은 partition으로 갈 것이므로) 이는 특정 consumer가 메시지를 보낸 순서대로 처리할 수 있도록 하지만, 만약 partition의 개수가 바뀐다면 rebalancing에 의해 더 이상 보장되지 않는다.
Kafka에서 한 broker에 있는 각 partition들은 파일 시스템 상에서 한 디렉토리로 매핑된다. 보통 그 디렉토리에는 인덱싱을 위한 파일과 실제 데이터를 위한 파일, 2개의 파일이 존재하게 된다. (Broker는 각 partition마다 그 2개의 파일들을 open하여 사용할 것이다.)
그래서 만약에 partition의 개수를 늘리면 늘릴수록, 필요한 파일 디스크립터, 핸들의 개수가 많아지므로 OS가 지원하는 최대 개수를 확인해야 한다. 보통 Kafka cluster는 한 broker 마다 30,000개의 파일 디스크립터를 사용하고 있다.
Kafka는 broker 간에 replication을 지원함으로써 안정성, 고가용성을 제공한다. 한 partition은 여러 개의 replica(복제본)을 가질 수 있는데 서로 다른 broker에 저장된다. 그 중 하나의 replica는 leader라 정의하고 나머지 replica는 follower라 정의한다. 내부적으로는 Kafka는 모든 replica 들을 자동으로 관리하고 sync를 맞춘다.
만약 leader를 가지고 있는 한 broker가 fail이 나면, Kafka는 자동적으로 follower를 가지고 있는 broker 들 중에 하나를 골라 leader로 사용하여 계속적인 서비스가 되도록 한다. 이 프로세스는 ZooKeeper안에서 관리되고 있는, 영향을 받는 partition에 대한 메타 정보를 업데이트하면서 진행된다.
어느 한 broker가 shut down 되었을 때, 다른 replica를 가지는 follower를 leader로 정하는 것이 아주 빠르게 진행된다. 보통 leader가 변경되는 것은 거의 몇 밀리세컨드 안에 진행된다.
그런데 이는 partition의 개수에 따라 그 시간이 증가할 수 있다. 만약 한 broker가 2000개의 partition을 가지고 있고 2개의 replica를 가지고 있다고 하면, 그 broker는 1000개의 leader를 가지고 있는 것이다. 만약 이 broker가 fail이 나면 1000개의 leader가 사용하지 못하는 상태가 될 것이다. 한 partition에 대해 leader를 변경하는 것이 5 밀리세컨드가 걸린다고 하면 1000개의 leader를 다시 지정하기 위해 5초가 걸린다는 것이다.
End-to-end latency는 producer에 의해 메시지가 partition을 통해 consumer에 의해 처리되는 시간을 말하는데, Kafka는 partition에 대해 복제가 완료된 상태여야만 consumer가 그 메시지를 partition으로부터 꺼내가도록 한다. 디폴트로 한 스레드가 메시지 데이터를 복제하는 것을 담당한다. 이는 partition의 개수가 많으면 많을수록 복제를 위한 시간으로 인해 producer가 보낸 메시지를 consumer가 더 늦게 받아서 처리될 수 있다는 것이다.
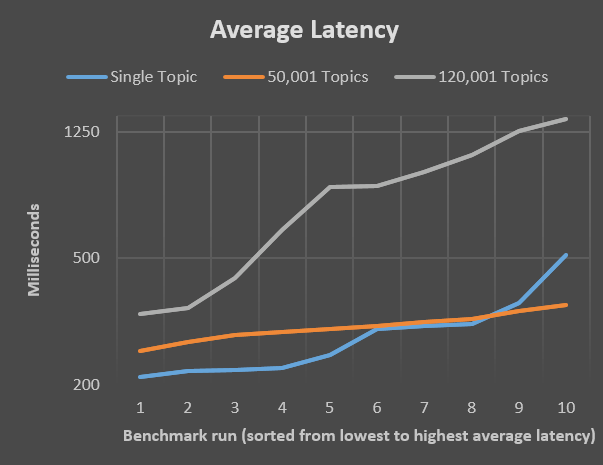
이 절에는 topic의 개수에 따라 미치는 latency 측면에서 벤치마크를 진행한 것을 정리한 것이다. 사실 Kafka FAQ에서는 많은 수의 topic을 가지는 것보다는 적은 개수의 큰 topic을 가지는 것을 권장한다.
여기서는 8GB RAM 및 140GB SSD를 장착한 Ubuntu 15.10을 사용한 환경에서 테스트를 진행하였다. 이 테스트에서는 10만개의 4KB 크기의 메시지를 보내며 10번을 반복하였다. 여기서는 topic이 1개, 그리고 50,001개 / 120,001개일 경우에 테스트를 진행한다.
다음과 같이 topic을 생성하였다.
$ bin/kafka-topics.sh \
--zookeeper 127.0.0.1:2181 \
--create \
--partitions 1 \
--replication-factor 1 \
--topic main
각 topic마다 partition을 하나로 주고, replication-factor도 하나로 주어 replication에 대해서는 고려하지 않기로 하였다.
그리고 다음 순으로 topic 수를 증가시킴으로써 50,001개 / 120,001개 일 때 테스트를 진행하였다.
for i in {1..50000}
do
bin/kafka-topics.sh \
--zookeeper 127.0.0.1:2181 \
--create \
--partitions 1 \
--replication-factor 1 \
--topic "test_$i"
done
for i in {50001..120000}
do
bin/kafka-topics.sh \
--zookeeper 127.0.0.1:2181 \
--create \
--partitions 1 \
--replication-factor 1 \
--topic "test_$i"
done
테스트는 다음과 같이 진행한다.
for i in {1..10}
do
echo
echo $i
bin/kafka-run-class.sh \
org.apache.kafka.clients.tools.ProducerPerformance \
main \
100000 \
4096 \
-1 \
acks=1 \
bootstrap.servers=127.0.0.1:9092 \
buffer.memory=67108864 \
batch.size=128000
sleep 5
done
다음과 같이 50,000개의 topic을 가질 때 latency의 평균 값이 topic이 1개일 때와 비슷한 것을 확인할 수 있었다.