

Spring Boot Reference Guide Part4, Chapter 32 messaging
먼저 Kafka를 활용한 messaging system을 Spring Boot에서 사용하기 전 개념을 짚고 넘어가도록 하자.

Producer가 Message를 Queue에 넣어두면, Consumer가 Message를 가져와 처리하는 방식이다. 위와 같은 구조로 통신을 하게 되면 Client와 동기 방식으로 데이터 통신을 하게 될 때 발생하는 병목현상을 완화할 수 있고, 서버의 성능을 개선시킬 수 있다.
여기서는 Apache Kafka를 통해 Spring Boot에서 messaging을 구현하겠다.
일단 먼저 Kafka가 설치되어 있어야 한다.
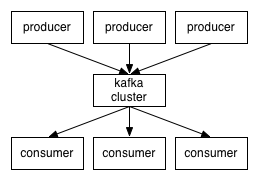
Kafka는 대용량 실시건 처리를 위해 사용하는 메시징 시스템으로, Pub-Sub 구조로 되어 있다. LinkedIn, Twitter, Netflix, Tumblr 등 대용량 데이터를 다루는 업체들이 주로 Kafka를 사용하고 있다. 물론 Kafka 단독으로 처리하지는 않고, Hadoop이나 HBase 등과 연동해서 활용하는 것이다.
비즈니스 소셜 네트워크로 유명한 LinkedIn은 메시징 및 로깅 처리를 위해 ActiveMQ와 Splunk를 사용하고 있었는데, LinkedIn이 글로벌 서비스로 성장하면서 처리할 데이터 양이 늘어남에 따라 기존의 기술들은 확장성이 떨어져서 LinkedIn이 확장성이 높고 신뢰성이 있는 Kafka를 개발하게 되었다.
이렇게 시작된 Kafka는 LinkedIn에서 빠른 처리 속도를 보장하는 분산 메시지 큐로서의 역할을 하게 된다. 이후 Apache Top Project에 등록되면서 점차 사용하는 회사가 늘어가게 된다.
Kafka의 가장 큰 특징은 다른 메시징 시스템과는 다르게 파일시스템을 이용한다는 점이다. 메모리에 저장하는 구조가 아니기 때문에 데이터 자체의 휘발성이 없으며 효율적으로 데이터를 보관할 수 있도록 구현되었다.
또한 시스템 자체가 Producer / Consumer / Broker로 매우 간단하게 구성되어 있다. Producer 는 데이터를 Kafka로 전달하는 역할을 하고, Consumer는 Kafka에 저장된 데이터를 가져오는 역할을 한다.
위의 그림과 같이 여러 개의 Producer와 Consumer를 구성할 수 있는데 데이터의 수집을 여러 곳에서 할 수 있고, 해당 데이터를 처리하는 것도 활용 범위에 따라 여러 개 만들어서 처리할 수 있다는 것이다.
Producer와 Consumer에 대한 API를 제공하면서 어떤 서비스와도 잘 결합되게 만들어져 있다는 점도 특징이다. 특히 빅데이터 분석에 많이 사용되는 Hadoop이나 HBase와 해당 Consumer를 구성해서 바로 연동할 수 있다.
Kafka에서는 토픽(Topic)을 설정해서 데이터를 전송하고, 각 토픽을 기준으로 파티션을 구성해 저장한다.
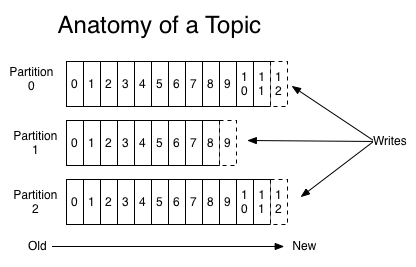
각 파티션에 들어온 순서대로 저장하고 Consumer에게 순차적으로 전달해 처리하게 된다. 물론 파티션에 따라 저장하는 정보의 양도 설정 값으로 조정 가능하다.
파티션 구조를 효과적으로 사용하고 신뢰성있는 시스템을 구성하기 위해 Kafka Cluster를 구성해야 한다. Kafka 클러스터를 구성하는 장점에 대해 LinkedIn의 엔지니어인 Jun Rao는 다음과 같이 이야기한다.
The benefits of Kafka replication
- A producer can continue to public messages during failure and it can choose between latency and durability, depending on the application.
- A consumer continues to receive the correct message in real time, even when there is failure.
마지막으로, Kafka Cluster를 관리하기 위해 주키퍼(Zookeeper)를 사용해서 각 노드를 모니터링한다. Kafka를 설치하면 Zookeeper도 함께 설치된다.
아래는 Kafka Cluster의 개념도이다.
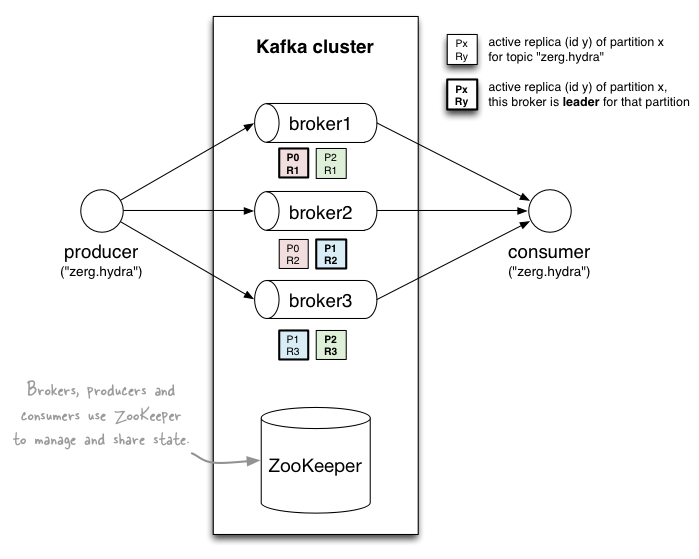
위 그림은 Kafka Cluster로 서버 3대를 이용하고 있으며 주키퍼로 모니터링하고 있다. “zerg.hydra” 라는 토픽으로 데이터를 전송하고 있고 파티션은 2개씩 사용한다.
broker1 을 보면 P0/P1 이 진하게 표시된 것을 알 수 있는데, 이는 브로커 1이 파티션 0의 리더 임을 나타내는 것이다. 정상적인 경우라면 파티션 0의 데이터를 읽기 위해 리더인 브로커 1의 데이터를 활용하게 되는데, 만약 브로커1에 문제가 발생한다면 파티션 0이 복제되어 있는 브로커 2의 데이터를 사용하게 될 것이다. 이러한 브로커 2와 같이 복제되어 있는 서버를 팔로워(follower)라고 한다.
신뢰성 있는 시스템을 위해 복제를 구성할 때 구글의 글로벌 분산데이터베이스인 스패너(Spanner)나 아파치의 주키퍼는 “Quorum Based” 방식으로 복제를 구성하고 있다.d d d 이 방식은 리더가 모든 팔로워에 데이터가 전송될 때까지 기다리지 않고, 대부분의 팔로워가 데이터를 수신하면 바로 리더에서 데이터를 처리하도록 하는 것이다. 만약 데이터 처리 중에 오류가 발생하면, 복제가 완료된 팔로워들 중 하나를 새로운 리더로 추천하여 처리하도록 한다.
먼저 Kafka와 주키퍼를 다음과 같이 설치하고 실행시킨다.
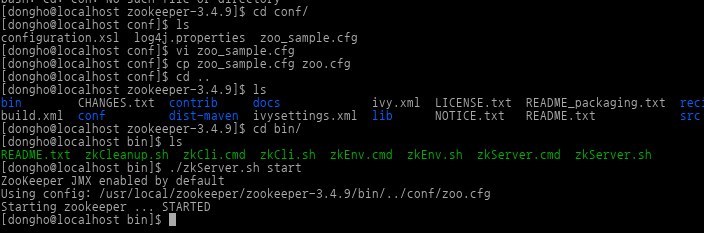
주키퍼를 다운로드 받아서 위와 같이 디폴트 configuration를 사용하여 시작시킨다.
Kafka를 다운로드 받아서 위와 같이 기본 설정된 configuration 파일로 daemon 형식으로 시작시킨다.
다음과 같이 pom.xml에 Kafka를 사용하기 위한 의존성을 추가한다.
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
Kafka를 사용하기 위해서는 KafkaTemplate 를 사용해야 하는데, 먼저 ProducerFactory에 property를 설정하여 KafkaTemplate의 생성자에 주입시켜주어야 한다.
ProducerFactory는 application.properties 파일로부터 property를 읽어 셋팅할 수도 있다. 여기서는 다음과 같이 application.properties에 Kafka 서버 주소에 대는해 property를 추가하였다.
kafka.bootstrap.servers=localhost:9092
그리고 다음과 같이 ProducerFactory를 만들어 KafkaTemplate 생성자에 주입시켜주자.
package com.nhnent.hellospringboot;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
@Configuration
public class SenderConfig {
@Value("${kafka.bootstrap.servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> producerConfig() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 5000);
return props;
}
@Bean
public ProducerFactory<Integer, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfig());
}
@Bean
public KafkaTemplate<Integer, String> kafkaTemplate() {
return new KafkaTemplate<Integer, String>(producerFactory());
}
@Bean
public Sender sender() {
return new Sender();
}
}
위에서 sender는 producer를 의미한다. 이 빈을 통해 Kafka를 이용하여 메시지를 보낼 것이다.
Kafka로부터 메시지를 받기 위해 @KafkaListener 라는 annotation을 사용하는데, 이를 위해 ConsumerFactory를 사용하여 KafkaListenerContainerFactory 라는 이름의 ConcurrentKafkaListenerContainerFactory 빈을 생성해주어야 한다.
다음 코드와 같이 KafkaListenerContainerFactory 빈을 생성해주자.
package com.nhnent.hellospringboot;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
@Configuration
@EnableKafka
public class ReceiverConfig {
@Value("${kafka.bootstrap.servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
IntegerDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "helloworld");
return props;
}
@Bean
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public ConcurrentKafkaListenerContainerFactory<Integer, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public Receiver receiver() {
return new Receiver();
}
}
위에서 receiver는 consumer를 의미한다. 이 빈을 통해 Kafka를 이용하여 메시지를 받을 것이다.
다음과 같이 Sender 를 추가한다. KafkaTemplate 의 send 메소드를 통해 asynchronous 하게 Kafka로 메시지를 보낼 것이다. 그리고 메시지를 보낸 결과를 확인할 수 있도록 callback 을 추가하여 성공 / 실패에 따라 로그 메시지를 출력하도록 하였다.
package com.nhnent.hellospringboot;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
public class Sender {
private static Logger logger = LoggerFactory.getLogger(Sender.class);
@Autowired
private KafkaTemplate<Integer, String> kafkaTemplate;
public void sendMessage(String topic, String message) {
ListenableFuture<SendResult<Integer, String>> future = kafkaTemplate.send(topic, message);
future.addCallback(
new ListenableFutureCallback<SendResult<Integer, String>>() {
@Override
public void onSuccess(SendResult<Integer, String> result) {
logger.info("sent message='{}' with offset={}",
message, result.getRecordMetadata().offset());
}
@Override
public void onFailure(Throwable ex) {
logger.error("unable to send message='{}'", message, ex);
}
}
);
}
}
다음으로, 메시지를 받아 처리할 Receiver를 추가한다. @KafkaListener annotation은 message를 받을 listener 를 생성하는데, 이는 아까 생성해둔 ConcurrentKafkaListenerContainerFactory 빈을 이용한다.
다음과 같이 메시지를 받아 처리할 메소드에 @KafkaListener annotation 을 붙인다.
package com.nhnent.hellospringboot;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
public class Receiver {
private static Logger logger = LoggerFactory.getLogger(Receiver.class);
@KafkaListener(topics = "helloworld.t")
public void receiveMessage(String message) {
logger.info("received message='{}'", message);
}
}
위의 예에서는 “helloworld.t” 라는 토픽으로부터 메시지를 받아 로그 메시지를 남긴다.
그럼 이제 Controller에 Kafka를 통해 메시지를 보낼 수 있도록 해보자. Kafka를 통해 메시지를 성공적으로 보내거나 받으면 console 창에 해당되는 로그메시지가 출력될 것이다.
@Controller
public class HelloController {
@Autowired
private Sender sender;
@RequestMapping("/kakfaTest/{value}")
public void kafkaTest(@PathVariable String value) {
sender.sendMessage("helloworld.t", value);
}
/kakfaTest path에 보낼 메시지를 붙여서 보내면 다음과 같은 로그 메시지가 출력되는 것을 확인할 수 있었다.
