

자바의 GC 알고리즘들을 설명하기에 앞서서, 이 알고리즘을 설명하는데에 있어서 필요한 기본 개념을 다시 살펴볼 필요가 있다. GC 알고리즘마다 다르긴 하지만 보통 GC 알고리즘들은 다음 두 가지 일에 포커싱을 맞춘다.
GC에 구현된 살아있는 객체를 조사하는 첫 번째 일은 Marking이라 부른다.
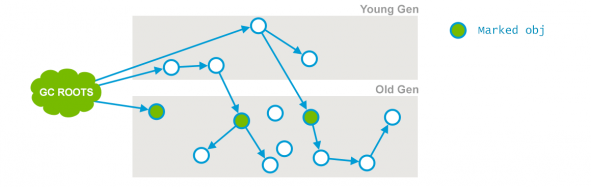
JVM에서 사용할 수 있는 모든 GC 알고리즘은 어느 객체가 살아있는지 조사하는 것부터 시작한다. 이 컨셉은 다음 그림에서 보여주는 JVM의 메모리 레이아웃을 통해 설명할 수 있다.
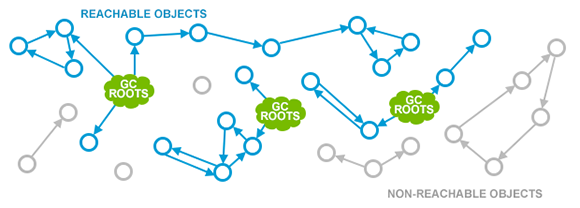
GC는 먼저 Garbage Collection Root (GC Root)라 불리는 특별한 객체를 정의한다. 다음은 GC Root라 불릴 수 있는 객체의 종류이다.
다음으로, GC Root로부터 시작하여 객체가 참조하는 것을 따라가며 (위 그림을 대변하자면, 객체 그래프를 순회하며) 살아 있는 모든 객체를 탐색한다. 탐색된 모든 객체는 Marked 된다.
위의 그림에서 푸른색 vertex로 표현된 것은 살아있는 객체라 판별된 객체이다. 이 단계가 끝나면 살아있는 모든 객체는 모두 Marking 되었을 것이며, 그 외의 모든 객체들은 (위의 그림에서 회색 그래프로 표현된 객체들) GC Root로부터 닿지 않는, 애플리케이션에서 더 이상 사용되지 않는 객체들로 간주된다. 이 객체들은 GC의 대상이며, 다음 단계에서 GC 알고리즘은 이 객체들이 점유한 메모리를 회수해야 한다.
Marking 단계에는 알아야 할 중요한 것은 다음과 같다.
이 단계가 끝나면 GC는 다음 단계인, 사용되지 않는 객체를 정리하는 단계로 넘어갈 수 있다.
더 이상 사용되지 않는 객체의 메모리를 회수하는 일은 GC 알고리즘마다 구현이 다르긴 하지만, 보통 이 단계는 Sweep, Compact, Copy로 나눌 수 있다.
Mark and Sweep에서 이 Sweep 단계는 Marking 단계가 끝난 후, GC Root 및 살아있는 객체로 표현되는 그래프에 포함되지 않는 객체들의 메모리 영역이 회수된다. 회수된 메모리 영역은 내부적으로 이 영역을 관리하는 free-list 라는 자료구조를 통해 관리된다. 아마도 이 자료구조는 다시 사용할 수 있는 영역과 그 것의 크기를 기록해두었을 것이다.

메모리 단편화 여부에 따라 전체 메모리 공간은 충분하나, 실제 객체 생성을 할 수 있는 충분한 연속적인 공간이 없다면 OOM이 발생할 수도 있다.
Mark-Sweep-Compact의 Compact 단계에서 실제로 살아있는, Marking 된 객체들을 메모리 영역의 처음부터 몰아넣음으로써 Mark and Sweep의 단점을 제거한다. 이는 실제 객체를 복사하고 이 객체들의 참조 정보를 업데이트하는 일을 수반하게 되는데, 이로 인해 애플리케이션 스레드가 멈추는 시간을 증가시킨다. 하지만 이 것을 통해 얻을 수 있는 이익은 여러 가지가 있다.

Mark and Copy의 Copy 단계는 Compact와 마찬가지로 살아 있는 객체를 어딘가로 복사한다는 점에서 비슷하지만, 객체가 이동해 갈 영역이 다르다. 메모리 영역을 여러 영역으로 나누고, 살아있는 객체를 다른 영역으로 복사하는 것이다. (ex. Eden -> Survivor / From survivor -> To survivor / Survivor -> Old)
Copy 단계도 Stop-The-World를 유발시킨다.
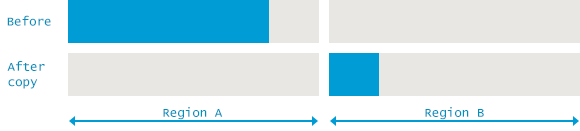
다른 영역으로 살아있는 객체를 옮기는 것이므로, Marking과 Copy 단계를 동시에 할 수 있다는 이점이 있다.
JVM 에서는 Generational Hypothesis 개념에 따라 Young 영역 및 Old 영역으로 힙 영역을 나누고, 각 영역에 대한 GC 알고리즘도 다르게 적용한다.
JVM에서 제공하는 GC 알고리즘은 옵션을 통해 선택할 수 있으며, 선택하지 않으면 디폴트로 지정된 GC 알고리즘을 사용하게 된다.
다음은 옵션에 따라 적용되는 GC 알고리즘을 나타낸 것이다.
| Young GC | Old GC | JVM Options |
|---|---|---|
| Incremental | Incremental | -Xincgc |
| Serial | Serial | -XX:+UseSerialGC |
| Parallel Scavenge | Serial | -XX:+UseParallelGC -XX:-UseParallelOldGC |
| Parallel New | Serial | N/A |
| Serial | Parallel Old | N/A |
| Parallel Scavenge | Parallel Old | -XX:+UseParallelGC -XX:+UseParallelOldGC |
| Parallel New | Parallel Old | N/A |
| Serial | CMS | -XX:-UseParNewGC -XX:+UseConcMarkSweepGC |
| Parallel Scavenge | CMS | N/A |
| Parallel New | CMS | -XX:+UseParNewGC -XX:+UseConcMarkSweepGC |
| G1 | G1 | -XX:+UseG1GC |
복잡하게 보이지만, 다음 4가지 케이스만 알아두면 된다. JVM Option이 없는 것들은 deprecated 되었거나, 실제 사용에 있어서는 적절하지 않은 알고리즘들이다.
이 알고리즘은 Young 영역에 대해서는 Mark-Copy, Old 영역에 대해서는 Mark-Sweep-Compact 를 사용한다. Serial GC 라는 이름을 통해 짐작할 수 있겠지만, 하나의 스레드에 의해 수행되며 Young 영역 및 Old 영역에 대한 GC는 모두 Stop The World 를 일으킨다.
JVM에서 이 알고리즘을 사용하기 위해서는 다음과 같이 JVM 파라미터를 설정하면 된다.
java -XX:+UseSerialGC com.mypackages.MyExecutableClass
하나의 스레드를 통해 수행되므로, 멀티 코어 CPU의 이점을 제대로 못살린다. CPU 코어가 몇 개이든 상관없이 이 GC를 사용할 때는 스레드 하나가 담당하게 된다. 따라서 CPU가 하나인, 작은 크기의 힙 영역을 사용하는 환경일 때만 사용하는 것이 권장된다. 멀티코어 / 큰 크기의 메모리를 갖는, 시스템 리소스를 많이 사용할 수 있는 서버 환경에서 이 GC를 사용하는 것은 권장되지 않는다.
다음은 Serial GC를 사용하였을 때의 GC log 이다. 참고로, GC log를 확인하기 위해 다음과 같이 JVM 파라미터를 설정한다.
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
2018-01-26T14:45:37.987-0200: 151.126: [GC (Allocation Failure) 151.126: [DefNew: 629119K->69888K(629120K), 0.0584157 secs] 1619346K->1273247K(2027264K), 0.0585007 secs] [Times: user=0.06 sys=0.00, real=0.06 secs]
2018-01-26T14:45:59.690-0200: 172.829: [GC (Allocation Failure) 172.829: [DefNew: 629120K->629120K(629120K), 0.0000372 secs]172.829: [Tenured: 1203359K->755802K(1398144K), 0.1855567 secs] 1832479K->755802K(2027264K), [Metaspace: 6741K->6741K(1056768K)], 0.1856954 secs] [Times: user=0.18 sys=0.00, real=0.18 secs]
단 두 줄밖에 되지 않는 로그이지만 많은 정보를 가지고 있다. 위 로그를 통해 두 번의 GC가 일어났다는 것을 알 수 있는데, 하나는 Young 영역에 대한 GC (Minor GC)이고 다른 하나는 힙 영역 전체에 대한 GC (Full GC)이다.
2018-01-26T14:45:37.987-0200: 151.126: [GC (Allocation Failure) 151.126: [DefNew: 629119K->69888K(629120K), 0.0584157 secs] 1619346K->1273247K(2027264K), 0.0585007 secs] [Times: user=0.06 sys=0.00, real=0.06 secs]
다음은 이 로그에서 알 수 있는 내용들이다.
2018-01-26T14:45:37.987-02001:151.1262:[GC3(Allocation Failure4) 151.126: [DefNew5:629119K->69888K6(629120K)7, 0.0584157 secs]1619346K->1273247K8(2027264K)9,0.0585007 secs10][Times: user=0.06 sys=0.00, real=0.06 secs]11
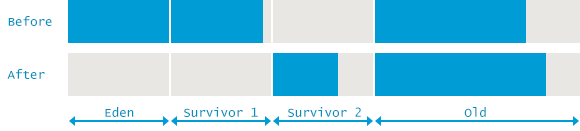
위의 로그를 통해 해당 GC 이벤트 전후로 Memory 사용량이 어떻게 변화하였는지 알 수 있다. GC가 일어나기 전에는 힙 영역의 사용량이 1,619,346K 이었다. 그리고 Young 영역의 사용량은 629,119K 인 것으로 보아, Old 영역의 사용량은 990,227K 이다.
GC가 일어난 후, Young 영역은 559,231K 의 빈 공간을 확보하였는데, 힙 영역의 사용량은 346,099K 밖에 줄어들지 않았다. 이를 통해 213,132K 만큼의 오브젝트들이 Young 영역에서 Old 영역으로 이동하였다는 것을 알 수 있다.
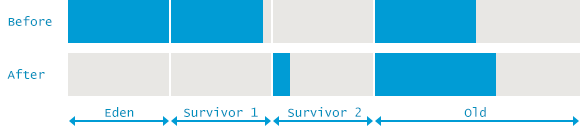
다음 2번째 줄의 로그는 Full GC에 대한 로그이다.
2018-01-26T14:45:59.690-0200: 172.829: [GC (Allocation Failure) 172.829: [DefNew: 629120K->629120K(629120K), 0.0000372 secs]172.829: [Tenured: 1203359K->755802K(1398144K), 0.1855567 secs] 1832479K->755802K(2027264K), [Metaspace: 6741K->6741K(1056768K)], 0.1856954 secs] [Times: user=0.18 sys=0.00, real=0.18 secs]
2018-01-26T14:45:59.690-02001: 172.8292:[GC (Allocation Failure) 172.829: [DefNew: 629120K->629120K(629120K), 0.0000372 secs3]172.829:[Tenured4: 1203359K->755802K 5(1398144K) 6,0.1855567 secs7] 1832479K->755802K8(2027264K)9,[Metaspace: 6741K->6741K(1056768K)]10 [Times: user=0.18 sys=0.00, real=0.18 secs]11
Minor GC 때와는 다른데, Young 영역 뿐만 아니라 Old 영역 및 Metaspace 영역에 대해서도 GC를 수행한다. GC 전후의 메모리 레이아웃은 다음 그림과 비슷할 것이다.
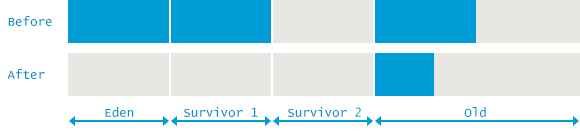
Serial GC와 마찬가지로 Young 영역은 Mark-Copy, Old 영역에 대해서는 Mark-Sweep-Compact 가 수행된다. 마찬가지로 모두 Stop The World를 일으킨다. 단 Serial GC와는 다른 점은 GC를 수행하는 여러 스레드가 병렬로 수행된다는 점이다. 따라서 Serial GC에 비해 걸리는 시간이 짧다.
병렬로 GC를 수행하여 빠르게 끝내는 전략으로 대용량의 힙 영역을 사용할 경우 유리하다.
GC를 수행하는 스레드의 개수는 -XX:ParallelGCThreads=NNN 라는 JVM 파라미터를 통해 설정할 수 있다. 기본 값은 JVM이 수행되는 환경의 CPU 코어 개수이다.
다음과 같이 파라미터를 설정하여 Parallel GC를 사용할 수있다. Young / Old 영역별로 수행되는 GC를 다르게 설정한다.
java -XX:+UseParallelGC com.mypackages.MyExecutableClass
java -XX:+UseParallelOldGC com.mypackages.MyExecutableClass
java -XX:+UseParallelGC -XX:+UseParallelOldGC com.mypackages.MyExecutableClass
Parallel GC는 애플리케이션의 Throughput이 아주 중요할 때 고려해 볼 수 있다.
Hotspot JVM에서는 여러 스레드에 의해 병렬로 GC가 수행될 경우, Young / Survivor 영역에서 Old 영역으로 객체를 이동시킬 때 동기화 문제를 회피하기 위해 PLAB(Parallel Allocation Buffer)를 사용한다. PLAB는 각 GC 스레드가 받는 Old 영역의 객체 할당 공간이다. 각 GC 스레드는 이를 통해 스레드 경합하지 않고 바로 Old 영역에 객체를 이동시킬 수 있다.
반면에, GC는 수행되는 도중에 중단되지 않기 때문에 어떤 이유로 GC가 수행되는 시간이 길어지면 여전히 애플리케이션 스레드도 장기간 멈출 수 있다. 즉, 애플리케이션의 Latency가 중요할 때는 다음에 설명할 CMS나 G1 GC도 고려해봐야 한다.
다음은 Parallel GC를 사용했을 때의 GC 로그이다.
2018-01-26T14:27:40.915-0200: 116.115: [GC (Allocation Failure) [PSYoungGen: 2694440K->1305132K(2796544K)] 9556775K->8438926K(11185152K), 0.2406675 secs] [Times: user=1.77 sys=0.01, real=0.24 secs]
2018-01-26T14:27:41.155-0200: 116.356: [Full GC (Ergonomics) [PSYoungGen: 1305132K->0K(2796544K)] [ParOldGen: 7133794K->6597672K(8388608K)] 8438926K->6597672K(11185152K), [Metaspace: 6745K->6745K(1056768K)], 0.9158801 secs] [Times: user=4.49 sys=0.64, real=0.92 secs]
2018-01-26T14:27:40.915-0200: 116.115: [GC (Allocation Failure) [PSYoungGen: 2694440K->1305132K(2796544K)] 9556775K->8438926K(11185152K), 0.2406675 secs] [Times: user=1.77 sys=0.01, real=0.24 secs]
2018-01-26T14:27:40.915-02001: 116.1152:[GC3(Allocation Failure4)[PSYoungGen5: 2694440K->1305132K6(2796544K)7]9556775K->8438926K8(11185152K)9, 0.2406675 secs10][Times: user=1.77 sys=0.01, real=0.24 secs]11
GC가 수행되기 전의 힙 사용량은 9,556,775K 였는데, 이 중 Young 영역의 사용량은 2,694,440K 이다.이는 GC가 수행되기 전, Old 영역의 사용량은 6,862,335K 라는 것을 의미한다.
GC가 수행되고 난 후에 Young 영역의 사용량은 1,389,308K 가 줄었지만 힙 영역의 사용량은 1,117,849K 밖에 줄어들지 않았다. 이를 통해 나머지 271,459K 크기에 해당하는 객체들은 모두 Young 영역에서 Old 영역으로 이동하였다는 것을 알 수 있다.
2018-01-26T14:27:41.155-0200: 116.356: [Full GC (Ergonomics) [PSYoungGen: 1305132K->0K(2796544K)] [ParOldGen: 7133794K->6597672K(8388608K)] 8438926K->6597672K(11185152K), [Metaspace: 6745K->6745K(1056768K)], 0.9158801 secs] [Times: user=4.49 sys=0.64, real=0.92 secs]
2018-01-26T14:27:41.155-02001:116.3562:[Full GC3 (Ergonomics4)[PSYoungGen: 1305132K->0K(2796544K)]5[ParOldGen6:7133794K->6597672K 7(8388608K)8] 8438926K->6597672K9(11185152K)10, [Metaspace: 6745K->6745K(1056768K)] 11, 0.9158801 secs12, [Times: user=4.49 sys=0.64, real=0.92 secs]13
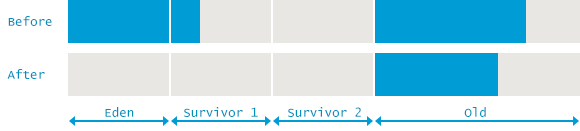
이 로그를 통해 Young 영역 뿐만 아니라 Old 및 Metaspace 영역에 대한 GC도 수행되었다는 것을 알 수 있다. GC 전후의 메모리 레이아웃은 다음 그림과 비슷할 것이다.
이 GC의 공식적인 이름은 “Mostly Concurrent Mark and Sweep Garbage Collector” 이다. Young 영역에 대해서는 Parallel GC와 마찬가지로 Mark-Copy 알고리즘을 사용하며 Stop The World를 일으킨다. 또한 멀티 스레드를 통해 병렬적으로 수행된다.
Old 영역에 대해서는 Mark-Sweep 알고리즘을 사용하는데, GC의 대부분 로직들이 애플리케이션 스레드와 “거의” 동시에 수행된다. (Monstly Concurrent) 이 Old 영역의 GC Collector는 Old 영역에 대한 GC가 발생할 때, 애플리케이션 스레드가 장시간 멈추는 것을 되도록 피하고자 디자인된 것이다. 다음 두 가지 방법을 통해, 애플리케이션 스레드가 멈추는 것을 막는다.
애플리케이션 스레드가 GC로 인해 멈추는 시간을 현저히 줄일 수 있다는 것이다. 각 GC 단계 중 특정 단계는 애플리케이션 스레드와 병렬로 수행함으로써, 애플리케이션 스레드가 멈추는 기간인 Stop The World를 분산시켜 결과적으로 애플리케이션 응답 시간을 개선한다.
당연히 애플리케이션 스레드와 병렬적으로 수행되는 단계에서는 GC 스레드도 CPU 코어를 사용하므로 애플리케이션 스레드와 CPU 자원을 얻기 위해 경쟁하게 된다. 기본적으로 이 GC 스레드 개수는 실제 환경의 CPU 코어 개수의 1/4 이다.
이 GC를 수행하기 위해 다음과 같이 JVM 파라미터를 사용한다.
java -XX:+UseConcMarkSweepGC com.mypackages.MyExecutableClass
Parallel GC와는 다르게, Latency가 중요할 때는 애플리케이션 스레드의 멈춤을 되도록 피하는 이 GC를 고려해볼 수 있다. 애플리케이션 스레드와 병렬적으로 수행되는 단계가 있는 이 GC를 사용함으로써, 애플리케이션의 responsiveness가 향상된다.
단, 모든 CPU 코어가 애플리케이션 스레드를 위해 사용되지 않고 GC를 위해 일부가 사용될 수도 있기 때문에, Parallel GC를 사용할 때보다는 Throughput이 줄어들 수 있다.
다음은 이 GC를 사용했을 때의 GC 로그이다. 여기서 첫 번째 로그는 Minor GC 로그이며, 나머지는 모두 Old 영역에 대한 GC 로그이다.
2018-01-26T16:23:07.219-0200: 64.322: [GC (Allocation Failure) 64.322: [ParNew: 613404K->68068K(613440K), 0.1020465 secs] 10885349K->10880154K(12514816K), 0.1021309 secs] [Times: user=0.78 sys=0.01, real=0.11 secs]
2018-01-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark: 10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2018-01-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
2018-01-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs]
2018-01-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
2018-01-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
2018-01-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
2018-01-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074 secs] [Times: user=0.20 sys=0.00, real=1.07 secs]
2018-01-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K (613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing, 0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub symbol table, 0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
2018-01-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
2018-01-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
2018-01-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
2018-01-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
2018-01-26T16:23:07.219-0200: 64.322: [GC (Allocation Failure) 64.322: [ParNew: 613404K->68068K(613440K), 0.1020465 secs] 10885349K->10880154K(12514816K), 0.1021309 secs] [Times: user=0.78 sys=0.01, real=0.11 secs]
2018-01-26T16:23:07.219-02001: 64.3222:[GC3(Allocation Failure4) 64.322: [ParNew5: 613404K->68068K6(613440K) 7, 0.1020465 secs8] 10885349K->10880154K 9(12514816K)10, 0.1021309 secs11][Times: user=0.78 sys=0.01, real=0.11 secs]12
위 로그에서 GC가 수행되기 전의 힙 사용량은 10,885,349K 이고 Young 영역의 사용량은 613,404K 인 것으로 나온다. 이를 통해 Old 영역의 사용량은 10,271,945K 인 것을 알 수 있다.
GC가 수행된 후, Young 영역의 사용량은 545,336K 가 줄었지만 힙 영역의 사용량은 5,195K 밖에 줄지 않았다. 이는 540,141K 크기의 객체들이 Young 영역에서 Old 영역으로 이동했다는 것을 알 수 있다.
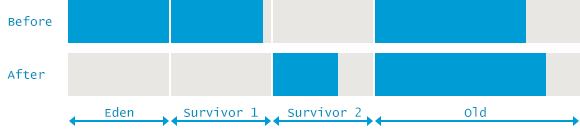
다음 로그를 보면 알 수 있겠지만 Serial GC나 Parallel GC와는 로그 형식이 완전히 다르다. 이 로그들은 Old 영역에 대해 GC를 수행하는, CMS GC의 각 단계에 대한 로그들이다.
2018-01-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark: 10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2018-01-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
2018-01-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs]
2018-01-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
2018-01-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
2018-01-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
2018-01-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074 secs] [Times: user=0.20 sys=0.00, real=1.07 secs]
2018-01-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K (613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing, 0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub symbol table, 0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
2018-01-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
2018-01-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
2018-01-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
2018-01-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
CMS GC에서 Old 영역에 대한 GC가 수행되는 도중에도, Young 영역에 대한 GC가 발생할 수 있다. 이 때 로그 상에서는 Minor GC 로그가 한데 섞여서 보일 것이다.
Phase 1: Initial Mark
2018-01-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark: 10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
CMS GC에서 Stop The World 를 일으키는 두 개의 단계 중 하나이다. 이 단계에서는 GC Root 로부터 바로 참조되거나, Young 영역의 살아있는 객체로부터 바로 참조되는 Old 영역의 객체를 mark 한다.
2018-01-26T16:23:07.321-0200: 64.421: [GC (CMS Initial Mark2[1 CMS-initial-mark: 10812086K3(11901376K)4] 10887844K5(12514816K)6, 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]7
Phase 2: Concurrent Mark
2018-01-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
2018-01-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs]
이 단계에서는 이전 단계인 “Initial Mark” 단계에서 mark 한 객체부터 시작해서 Old 영역을 순회하면서 살아있는 모든 객체들을 mark 한다. Concurrent 라는 이름이 나타내는 것처럼, 이 단계에서 애플리케이션 스레드를 멈추지 않고 동작한다.
이 단계에서 살아있는 모든 객체가 완전히 mark 되지 않는다. 애플리케이션 스레드가 돌고 있으므로, 애플리케이션의 객체들의 상태는 계속 변화할 수 있다.
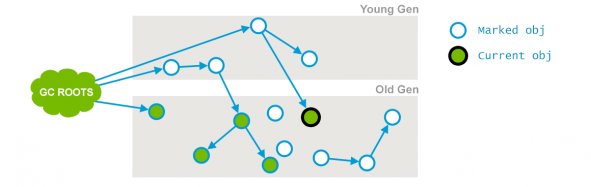
위의 그림에서 볼 수 있듯이, 검은색 테두리인 “Current Object”의 그래프가 변하였다. (Mark 하고 있는 도중에, Current Object가 가지고 있던 참조 객체가 지워졌다는 것이다.)
2018-01-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start] 2018-01-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark1: 035/0.035 secs2] [Times: user=0.07 sys=0.00, real=0.03 secs]3
Phase 3: Concurrent Preclean
2018-01-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
2018-01-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
이 단계도 “Concurrent” 단계로서, 애플리케이션 스레드를 멈추지 않고 동작한다.
이전 단계에서 애플리케이션 스레드와 동시에 동작하였기 때문에, 객체들 간의 참조 그래프가 변했을 수 있다. (Young 영역의 GC가 발생되어 Old 영역으로 객체가 이동되거나, 새로운 객체가 생성되었을 경우. CMS의 Old 영역 GC 도중에도 Young 영역에 대한 GC가 일어날 수 있다.) 이럴 때마다 JVM은 소위 Card라 불리는 힙 영역 중 특정 영역에 dirty로 표시해두는 “Card Marking” 이라는 기법을 사용한다.
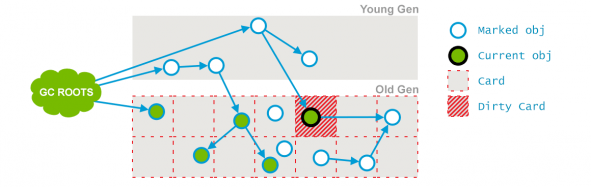
“Concurrent Preclean” 단계에서는 이 Card 안에 있는 “dirty 한” 객체로부터 참조되고 있는 객체들을 mark 한다. 그리고 Card의 dirty 표시는 지워질 것이다.
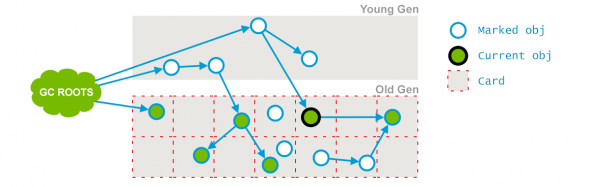
마지막으로 “Final Remark” 단계를 위해 필요한 작업을 수행한다.
2018-01-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start] 2018-01-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean1: 0.016/0.016 secs2] [Times: user=0.02 sys=0.00, real=0.02 secs]3
Phase 4: Concurrent Abortable Preclean
2018-01-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
2018-01-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074 secs] [Times: user=0.20 sys=0.00, real=1.07 secs]
이 단계도 애플리케이션 스레드와 같이 동작하는 단계이며, Stop The World를 일으키는 “Final Remark” 단계를 되도록 빨리 끝내기 위해서 수행된다.
Young (Eden) 영역의 사용량이 “CMSScheduleRemarkEdenSizeThreshold” 보다 높으면, “CMSScheduleRemarkEdenPenetration”에 설정된 비율보다 사용량이 낮아질 떄까지 precleaning, 즉 변화한 객체들을 계속 스캔한다.
2018-01-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start] 2018-01-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean1: 0.167/1.074 secs2] [Times: user=0.20 sys=0.00, real=1.07 secs]3
이 단계에서 수행한 결과에 따라, 다음 단계인 “Final Remark”의 수행시간에 큰 영향을 끼친다.
Phase 5: Final Remark
2018-01-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K (613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing, 0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub symbol table, 0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
이 단계는 Stop The World를 일으키는 두 번째 단계로써, Old 영역에 있는 살아있는 모든 객체들을 완전히 mark 한다.
이전 단계들은 애플리케이션 스레드와 병렬적으로 수행했기 때문에, 애플리케이션의 동작에 따라 변화하는 객체들의 상태를 빠르게 반영하지 못했을 수 있다. 따라서 이 단계에서 다시 Stop The World를 통해 애플리케이션 스레드를 잠시 멈춤으로써, 객체들의 상태를 완전히 반영하는 것이다.
CMS GC는 이 단계를 되도록 Young 영역이 거의 비워져있을 때 수행하게 하도록 하여, Stop The World 를 일으키는 동작이 연쇄적으로 발생하는 것을 방지한다. (Young 영역이 거의 가득차 있을 경우, 이 단계가 끝나고 다시 Young 영역의 GC가 발생하여 Stop The World를 일으킬 수 있다.)
2018-01-26T16:23:08.447-0200: 65.5501: [GC (CMS Final Remark2) [YG occupancy: 387920 K (613440 K)3]65.550: [Rescan (parallel) , 0.0085125 secs]465.559: [weak refs processing, 0.0000243 secs]65.5595: [class unloading, 0.0013120 secs]65.5606: [scrub string table, 0.0001759 secs7][1 CMS-remark: 10812086K(11901376K)8] 11200006K(12514816K) 9, 0.0110730 secs10] [[Times: user=0.06 sys=0.00, real=0.01 secs]11
Mark 단계가 끝나면 Old 영역에 있는 모든 살아있는 객체들은 mark 되었을 것이며, 이제 Old 영역을 청소함으로써 새로 객체를 할당하기 위한 공간을 확보할 수 있다.
Phase 6: Concurrent Sweep
2018-01-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
2018-01-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
애플리케이션 스레드와 병렬적으로 수행되며, 사용하지 않는 객체들을 정리하여 빈 공간을 확보한다.
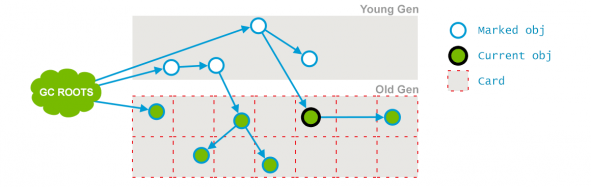
2018-01-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2018-01-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep1: 0.027/0.027 secs2] [[Times: user=0.03 sys=0.00, real=0.03 secs] 3
Phase 7: Concurrent Reset
2018-01-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
2018-01-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
CMS 알고리즘 내부에서 사용하는 데이터들을 리셋하고, 다음 GC 사이클을 준비해놓는다.
2018-01-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2018-01-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset1: 0.012/0.012 secs2] [[Times: user=0.01 sys=0.00, real=0.01 secs]3
CMS GC는 이렇게 각 단계를 나누어, 애플리케이션 스레드와 병렬적으로 GC 동작을 수행함으로써 Stop The World로 인해 애플리케이션이 멈추는 시간을 줄이거나 분산시킨다.
하지만 CMS GC도 단점이 있는데, Old 영역에 대한 Compaction을 수행하지 않음으로써 Old 영역에서 단편화가 발생할 수 있다. 그리고 또한 큰 힙 영역을 가지는 환경에서는 애플리케이션 스레드가 멈추는 시간을 예측하기가 힘들 수 있다.
G1 알고리즘의 목표 중 하나는, GC로 인해 애플리케이션 스레드가 멈추는 Stop The World의 시간과 빈도를 예측하게 만들고, 이를 설정할 수 있도록 하는 것이다.
사실상 G1(Garbage-First)은 soft real-time garbage collector로서, 사용자가 설정한대로 garbage collection의 성능이나 GC로 인해 멈추는 시간을 거의 맞출 수 있다. 그래서 Stop The World의 시간을 몇 밀리세컨드 내로 발생하도록 조정할 수 있으며 G1 GC는 사용자가 설정한, 이 “목표”에 따라 최선을 다한다. (최대한 사용자가 의도한대로 동작한다는 것이다. 그럴 수 있다면 hard real-time garbage collector가 될 것이다.)
이를 위해 G1은 다음과 같이 구현된다.
앞서 살펴봤던 연속된 Young 영역 및 Old 영역으로 힙 영역을 관리하지 않는다. 대신 힙 영역을 일정한 크기의 작은 공간(region)으로 나눈다. (기본 2048개의 region이다.) 각 region은 Eden이거나 Survivor, Old 가 된다. 물론 논리적으로 봤을 때, Eden 및 Survivor에 해당하는 region을 합쳐서 본다면 Young 영역으로 볼 수 있다. Old 또한 마찬가지.

이렇게 구현한다면 garbage collector 입장에서는 전체 힙 영역을 대상으로 하는 것이 아니라 여러 region 영역만을 대상으로 수행할 수 있다. 한 GC 사이클에 모든 Young / Old 영역에 대해 GC를 수행할 필요가 없다는 것이다.
G1 GC는 잘개 나누어진 각 region들을 collection set이라 불리는 것으로 분류하여, 분류된 region들만을 고려하여 garbage collection을 수행한다.
Young 영역에 해당하는 모든 region에 대해서는 collection set에 모두 포함되어 한 GC 사이클에 모두 GC가 수행되며, Old 영역의 경우 collection set에 포함되어 garbage collection의 대상이 되거나 안될 수 있다.
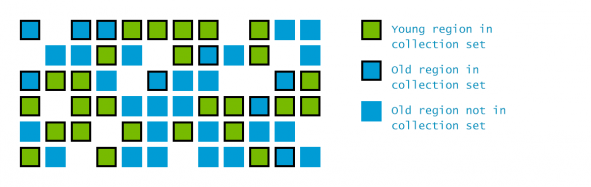
또한 GC를 수행할 때, 각 region이 가지고 있는 살아있는 객체의 수를 조사하는데 이 정보는 애플리케이션 스레드와 동시에 수행되는 concurrent phase에 수행되어 Collection Set을 만들 때 참조된다.
G1 GC는 살아있는 객체가 아닌 GC 대상이 되는, 더 이상 사용하지 않는 객체가 많은 region부터 collection set에 포함시킨다.
따라서 이 GC의 이름이 Garbage-First 인 것이다.
G1 GC를 사용하기 위해서는 다음과 같이 JVM 파라미터를 설정한다.
java -XX:+UseG1GC com.mypackages.MyExecutableClass
애플리케이션이 처음 시작되었을 때는, G1은 GC를 위해 참조될 정보가 없기 때문에 Young 영역에 대해서만 수행하는 fully-young 모드로 동작한다.
Young 영역이 가득찼을 경우에 살아있는 객체를 Marking하기 위해 애플리케이션 스레드는 잠시 멈추게 되고, Young 영역에 있는 살아있는 객체들은 Survivor 영역이나 Survivor 영역 근처의 region에 이동시킨다. 객체 이동하는 동작을 Evacuation이라고 부르는데, 이전에 봤던 GC 알고리즘들과 거의 동일하다.
Evacuation에 대한 로그는 좀 많은데, 여기서는 fully-young 모드와는 관계가 없는 로그를 빼고 살펴보도록 한다. 해당 로그들은 애플리케이션 스레드와 동시에 동작하는 concurrent 단계일 때 다시 볼 것이다. 또한 GC 스레드가 병렬로 동작할 때 남는 로그(Parallel) 들과 “Other” 단계일 때의 로그도 나누어서 볼 것이다.
0.134: [GC pause (G1 Evacuation Pause) (young), 0.0144119 secs]1
[Parallel Time: 13.9 ms, GC Workers: 8]2
…3
[Code Root Fixup: 0.0 ms]4
[Code Root Purge: 0.0 ms]5
[Clear CT: 0.1 ms]
[Other: 0.4 ms]6
…7
[Eden: 24.0M(24.0M)->0.0B(13.0M) 8Survivors: 0.0B->3072.0K 9Heap: 24.0M(256.0M)->21.9M(256.0M)]10
[Times: user=0.04 sys=0.04, real=0.02 secs] 11
이 단계에서 제일 시간이 많이 걸린 것은, GC 스레드들에 의해 병렬적으로 동작한 일들이다. 다음과 같이 로그 상에서 확인할 수 있다.
[Parallel Time: 13.9 ms, GC Workers: 8]1
[GC Worker Start (ms)2: Min: 134.0, Avg: 134.1, Max: 134.1, Diff: 0.1]
[Ext Root Scanning (ms)3: Min: 0.1, Avg: 0.2, Max: 0.3, Diff: 0.2, Sum: 1.2]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms)4: Min: 0.0, Avg: 0.0, Max: 0.2, Diff: 0.2, Sum: 0.2]
[Object Copy (ms)5: Min: 10.8, Avg: 12.1, Max: 12.6, Diff: 1.9, Sum: 96.5]
[Termination (ms)6: Min: 0.8, Avg: 1.5, Max: 2.8, Diff: 1.9, Sum: 12.2]
[Termination Attempts7: Min: 173, Avg: 293.2, Max: 362, Diff: 189, Sum: 2346]
[GC Worker Other (ms)8: Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
GC Worker Total (ms)9: Min: 13.7, Avg: 13.8, Max: 13.8, Diff: 0.1, Sum: 110.2]
[GC Worker End (ms)10: Min: 147.8, Avg: 147.8, Max: 147.8, Diff: 0.0]
위의 동작말고도 Evacuation 단계에서 자잘한 일들도 많이 수행되었는데 다음과 같다.
[Other: 0.4 ms]1
[Choose CSet: 0.0 ms]
[Ref Proc: 0.2 ms]2
[Ref Enq: 0.0 ms]3
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]4
G1 GC 알고리즘의 컨셉은 CMS GC와 많이 비슷하기 때문에, CMS 알고리즘을 잘 이해하고 있다면 이 알고리즘을 이해하는데도 별 어려움이 없을 것이다. 비록 디테일한 구현은 다르겠지만, 애플리케이션 스레드와 동시에 동작하는 Concurrent Mark는 매우 비슷하다.
G1 GC의 Concurrent Mark는 Snapshot-At-The-Beginning 접근법에 따라, mark 단계의 시작점에서, 비록 애플리케이션 스레드의 동작에 따라 객체의 그래프가 변하더라도, 살아있는 모든 객체를 mark 를 시도한다. 이 정보는 각 region의 살아있는 객체들의 정보를 유지할 수 있게 하고 Collection Set를 만드는데 참조된다.
Concurrent Marking 단계는 힙 영역의 사용량이 일정 이상이 되었을 때 시작된다. 디폴트는 힙 전체 영역의 45%이지만, InitiatingHeapOccupancyPercent 라는 JVM 옵션을 통해 변경할 수 있다. CMS GC랑 비슷하게 이 단계도 여러 세부 단계로 나누어 수행되는데 어떤 단계는 애플리케이션과 동시에 동작하지만, 어떤 단계는 Stop-The-World 를 유발한다.
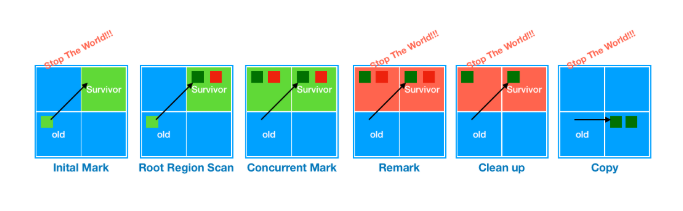
Phase 1: Initial Mark
이 단계에서는 GC Root로부터 바로 참조되는 살아 있는 객체를 mark 한다. (Old region의 객체로부터 참조되는 Survivor Region mark) CMS GC는 Stop The World를 일으키는 단계였지만, G1 GC는 Evacuation 단계 (Young GC)로부터 트리거되기 때문에 (piggy-backed) 그 오버헤드는 덜하다. 다음 로그와 같이 확인할 수 있다.
1.631: [GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0062656 secs]
Phase 2: Root Region Scan
이 단계에서는 Root region (Survivor region)에 속해 있는 살아있는 모든 객체를 mark 한다. 애플리케이션 스레드와 동시에 동작하며, Survivor region을 건드리는 다음 Evacuation 단계 (Young GC)가 일어나기 전까지 반드시 완료해야 한다.
1.362: [GC concurrent-root-region-scan-start]
1.364: [GC concurrent-root-region-scan-end, 0.0028513 secs]
Phase 3: Concurrent Mark
CMS GC와 매우 유사하게, 객체 그래프를 따라 힙 영역의 모든 살아있는 객체를 식별하여 특별한 비트맵을 이용하여 mark 해둔다. 애플리케이션 스레드와 동시에 동작한다.
만약 이 단계에서 비어 있는 region (살아있는 객체를 보유하고 있지 않은)이 발견되면 즉시 회수된다.
1.364: [GC concurrent-mark-start]
1.645: [GC concurrent-mark-end, 0.2803470 secs]
Phase 4: Remark
이 단계는 Stop The World를 일으키는 단계로, mark 하는 단계를 완료하는 단계이다. 애플리케이션 스레드를 잠시 멈추고 log buffer에 있던 정보를 참조하여 객체 상태 업데이트를 완료한다.
또한 모든 region에 대해서 가지고 있는 살아있는 객체의 수를 나타내는 live stat (Region Liveness)를 계산한다.
1.645: [GC remark 1.645: [Finalize Marking, 0.0009461 secs] 1.646: [GC ref-proc, 0.0000417 secs] 1.646: [Unloading, 0.0011301 secs], 0.0074056 secs]
[Times: user=0.01 sys=0.00, real=0.01 secs]
Phase 5: Cleanup / Copying
각 로직에 따라 애플리케이션 스레드와 동시에 수행되는 것도 있고, Stop The World를 일으키는 것도 있다. 이 단계에서 먼저 다음 GC를 위해 힙 영역에 있는 모든 살아있는 객체 정보를 조사해둔다.
각 region의 liveness, 즉 살아 있는 객체가 가장 적은 region을 선택하여 collect 한다.
이 단계에 수행되는, 완전히 비어 있는 region을 회수하는 것이나 살아있는 객체의 상태를 계산하는 것과 같은 일부 로직을 봤을 때 애플리케이션 스레드와 동시에 수행되어도 문제없을 것 같지만, 애플리케이션 스레드의 방해없이 GC 작업을 완전히 마무리 짓기 위해 Stop The World를 일으킨다.
Young / Old region은 이 시점에 같이 collect 된다.
1.652: [GC cleanup 1213M->1213M(1885M), 0.0030492 secs]
[Times: user=0.01 sys=0.00, real=0.00 secs]