

개발을 진행하면서 예외 핸들링에 관한 여러 문제점들 중에 하나는 언제, 그리고 어떻게 처리를 해야하느냐는 것이다.
특히 Java 에서 예외는 Exception 클래스로부터 상속받는 checked exception들과, RuntimeException 을 상속받는 unchecked exception으로 구분하고 있다.
이 Checked Exception은, 다른 언어 (C++이나 C#)에서는 모든 예외가 unchecked 인 상황에서 Java 언어만이 가지는 독특한 특징이라 할 수 있다. 반드시 처리하거나 throws로 명시하여 전달해야 하는 것을 강제한다. 여기에서는 Java 에서의 예외에 대한 설명과 효과적인 예외처리 방법, 각종 안티패턴들을 설명한다.
여기서 언급되는 클라이언트 라함은, 예외를 발생시키는 메소드나 API를 사용하는 쪽을 말한다.
앞서 언급하였듯이 Java에서는 예외에 대한 클래스들을 다음과 같이 정의하고 있다.
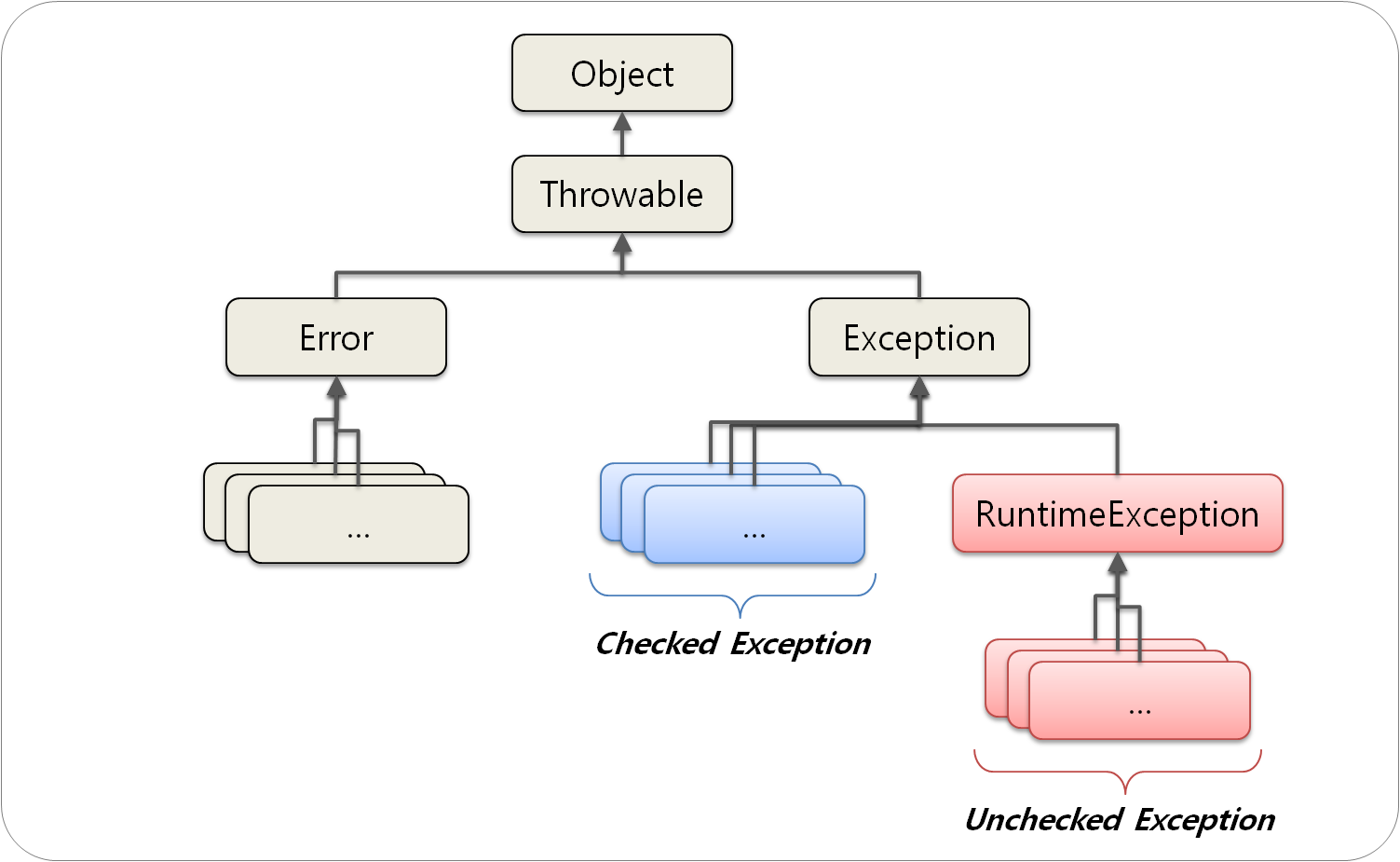
위와 같이 모든 예외 클래스는 Throwable 클래스를 상속받으며 이 클래스를 상속받는 서브 클래스는 Error 와 Exception 이 있다.
Error 는 시스템 레벨에서, 즉 메모리 부족과 같은 시스템에 뭔가 비정상적인 상황이 발생했을 경우에 사용된다. JVM에서 주로 발생시키고 애플리케이션 코드에서 이 것을 잡으려고 하면 안된다. OutOfMemoryError 나 ThreadDeath 같은 에러는 애플리케이션 코드에서 catch 로 잡아봤자 대응 방법이 없다.
Error가 아닌 모든 클래스는 Exception 클래스로부터 상속받으며, 이 클래스들은 Checked Exception 과 Unchecked Exception 으로 구분된다. 위 그림에서 RuntimeException 클래스를 상속받는가, 아닌가에 따라 Checked Exception과 Unchecked Exception 으로 나뉘어진다.
이 Checked Exception 과 Unchecked Exception 의 가장 명확한 구분 기준은 후 처리가 필요한 것인가 이다. Java에서는 Checked Exception 에 대해서 반드시 try-catch 블록을 사용하거나 throws 를 통해 해당 예외를 전달하도록 강제하며, Unchecked Exception은 명시적인 예외 처리를 하지 않아도 된다.
Unchecked Exception 은 명시적인 예외 처리를 하지 않아도 되지만, 이런 예외는 미리 조건을 체크하고 주의 깊게 코드를 작성한다면 피할 수 있는 경우가 대부분이다. 피할 수 있지만 개발자가 부주의해서 일어나는 상황에 대해 발생하도록 만든 것이 Unchecked Exception 이다.
하위 계층에서 던져진 Checked Exception 은 이 예외를 반드시 잡아내거나 다시 throw 해야된다는 것을 강제하는데, 상위 계층에서 이런 예외들을 효율적으로 처리할 수 없는 경우에는 원하지 않는 짐이 되어버린다.
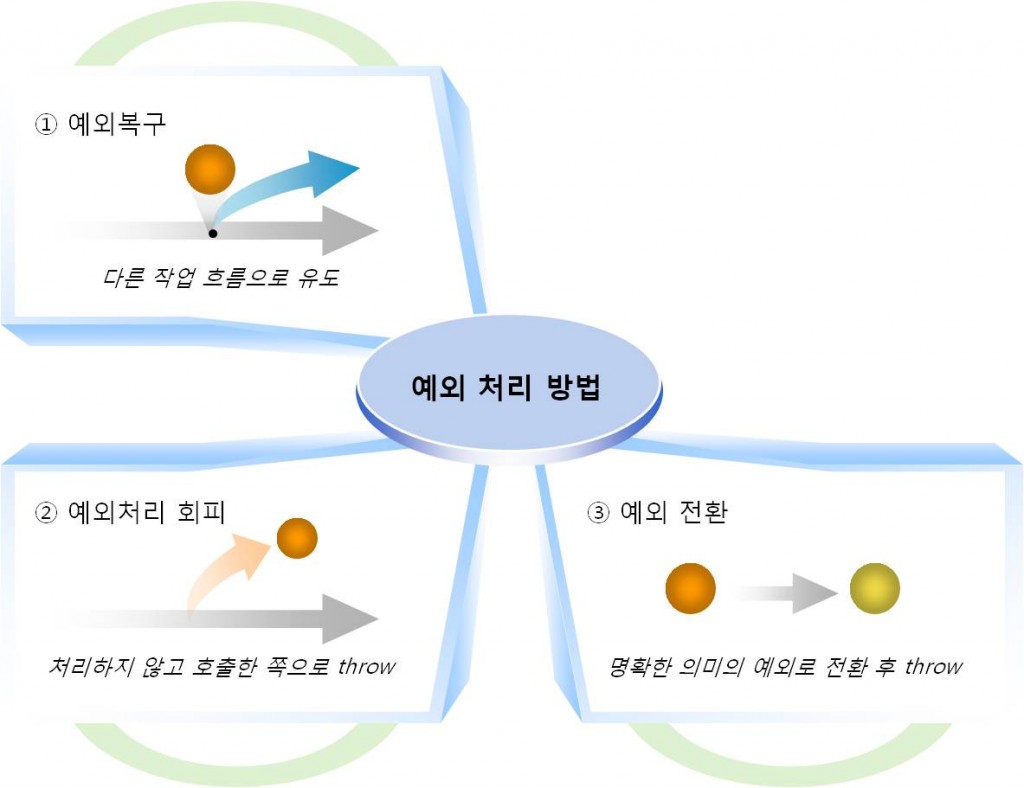
예외가 발생했을 때, 보편적으로 이 예외를 처리하는 방법은 다음과 같이 3가지 방법이 있다.
public void testException(int retryCount) {
int i = 0;
while (i < retryCount) {
try {
// do something.
return;
} catch (SomeException e) {
// handling exception.
} finally {
// clean up resource.
}
}
}
예외 복구의 핵심은 예외가 발생해도 애플리케이션은 정상적인 흐름으로 진행된다는 것이다. 위의 예제는 재시도를 통해 예외를 복구하는 코드이다. 복구를 통해 다시 애플리케이션이 정상적인 흐름을 타게하거나 미리 의도된 다른 흐름으로 유도시키도록 하면 비록 예외가 발생해도 정상적으로 작업을 마칠 수 있다.
public void add() throws SQLException {
...
}
위의 코드는 해당 Exception 이 발생했을 경우, caller에게 그냥 전달만 한다. 이렇게 구현할 때는 호출한 쪽에서 해당 예외를 반드시 처리한다는 확신이 있거나 효율적으로 처리를 할 수 있을 때에만 해야 한다.
public void function() {
try {
...
} catch (SQLException e) {
throw new DuplicateUserException(e);
}
}
예외 전환은 위 코드처럼 예외를 잡아서 다른 특정 예외로 전달하는 것이다. 호출한 쪽에서 이 예외를 받아 처리할 때 좀 더 명확하게 처리할 수 있을 때의 방법이다. 또한 Checked Exception이 발생했을 때, 이를 RuntimeException 으로 묶어 전달함으로서 다른 쪽에서 일일이 예외를 선언할 필요가 없도록 할 수도 있다.
개발자로서는 우리는 어떤 문제를 해결하는 질적으로 우수한 코드를 작성하기를 바란다. 그렇지만 예외는 우리의 코드에게 일종의 부작용을 가져옴으로써, 이 것을 처리하기 위해 자신들 고유의 해결책을 찾게 된다.
예외가 발생하는 상황은 다음과 같은 3가지의 경우이다.
Exceptions due to programming errors (프로그래밍 에러로 인한 예외의 발생)
이 예외들은 프로그래밍적 오류로 인해 발생한다. (NullPointerException과 같은 생성되지 않은 객체의 변수나 메소드 사용하거나 IllegalArgumentException과 같이 파라미터를 잘못 사용한 경우). 이런 원인으로 발생하는 예외는 어떤 조치를 취할 수가 없다.
Exceptions due to client code errors (클라이언트 코드들의 에러로 인해 발생하는 예외)
제공되는 API에서 허용되지 않는 것들을 시도하려고 했을 때, 만약 예외가 제공하는 유용한 정보들이 있다면 클라이언트에서는 다른 대안적인 행동을 취할 수 있게 된다.
Exceptions due to resource failures (리소스 자체의 문제로 인해 발생하는 예외)
예외들은 프로그램이 사용한 리소스들을 불러들이는데 실패 혹은 리소스 자체의 문제로 인해 발생할 수 있다. 클라이언트는 해당 리소스를 사용하기 위해 일정 시간 후에 다시 시도한다거나, 실패를 로그로 남길 수도 있다.
Checked Exception과 Unchecked Exception 중 어떤 것을 쓸 것인지를 결정할 때 먼저 다음을 생각해야 한다.
“클라이언트 코드, 즉 호출자가 예외가 발생했을 때 어떤 조치를 취할 수 있는가?”
만약 코드가 예외 발생으로부터 프로그램을 복구하기 위해서 다른 대안을 취할 수 있다면 Checked Exception으로 예외를 구성하는 것이 좋다. 만약 이 예외로부터 효과적은 일을 할 수 없다면 Unchecked Exception 으로 구성해야 한다.
| 예외 발생시, 클라이언트 코드의 반응 | 예외 타입 |
|---|---|
| 클라이언트가 조치를 취할 수 없음 | Unchecked Exception |
| 예외가 주는 정보를 통해 어느정도의 예외 복구 조치를 취할 수 있음 | Checked Exception |
캡슐화를 유지하자
구현에서 정의된 Checked Exception 들이 상위 계층으로 전달되게 하지 않는 것이 좋다. 예를 들어 SQLException을 data를 다루는 코드에서 이 예외를 전혀 알지 못하는 비즈니스 계층으로 전달하는 것은 좋지 않다. 비즈니스 계층에서는 이 예외에 대해 전혀 알 필요가 없다.
이 상황에서 다음 두 가지 방안 중 하나를 선택할 수 있다.
가령 다음의 예를 살펴보자
public void dataAccessCode() {
try {
...
} catch (SQLException e) {
e.printStackTrace();
}
}
위의 catch 블록은 단순히 예외에 대한 정보를 출력할 뿐 아무것도 하지 않는다. 클라이언트 코드가 아무 것도 할 수 없다는 것이다. 이런 경우에는 다음과 같이 작성하는 것이 좋을 수 있다.
public void dataAccessCode() {
try {
...
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
위의 코드는 SQLException을 RuntimeException 으로 변환하였다. 그러면 비즈니스 계층에서는 이 예외를 처리할 필요가 전혀 없으므로 비즈니스 계층의 코드가 복잡해지지 않을 것이다.
만약 이 예외를 의미있는 조치를 취할 수 있다면 Checked Exception 으로 변환해야 한다.
클라이언트 코드로 충분한 정보를 전해줄 수 없다면 새로운 사용자 정의 예외를 만들지 마라.
다음 코드와 같이 사용자 정의 예외를 정의한다면 아무런 유용한 정보를 주지 못한다.
public class DuplicateUserException extends Exception {
}
우리는 이 예외 클래스에 다음과 같이 메소드를 추가함으로써 클라이언트 코드가 유용한 정보를 얻을 수 있도록 도움을 줄 수 있다.
public class DuplicateUserException extends Exception {
public DuplicateUserException(String username) {
...
}
public String requestedUserName() {
...
}
public String[] availableNames() {
...
}
}
만약 클라이언트로 정보를 주지 못한다면 사용자 정의 예외를 만들지 말고, 표준 예외를 발생시키는 것만으로도 충분한다.
throw new Exception("Username already exists.");
흐름제어 를 위해 예외를 사용하지 마라.
아래의 코드는 MaximumCountReachedException 이라는 사용자 정의 예외가 흐름을 제어하는데 사용되었다.
public void useExceptionsForFlowControl() {
try {
while (true) {
increaseCount();
}
} catch (MaximumCountReachedException e) {
...
}
}
public void increaseCount() throws MaximumCountReachedException {
if (count >= 5000) {
throw new MaximumCountReachedException();
}
}
위의 useExceptionsForFlowControl 메소드는 카운트를 증가시켜 예외가 발생할 때까지 무한루프를 돌리고 있다. 이렇게 코드를 작성하면 읽기 어렵게 만들뿐만 아니라, 수행속도까지 느리게 만들어버린다. (JVM의 최적화 대상에서도 빠질 수가 있다.)
예외처리는 예외가 발생하는 상황에서만 사용해야 한다.
이 절에서는 예외 처리와 관련하여 4가지의 anti pattern 들을 소개한다.
public void aMethod() throws Exception {
doSomething();
}
public void callerMethod() throws Exception {
aMethod();
}
public void callersCallerMethod() throws Exception {
callerMethod();
}
위의 코드는 예외 처리는 진행하지 않고 계속 throws 를 통해 상위 계층으로 던짐으로써 클라이언트 코드가 복잡해지게 만들고 있다. 결국 아무도 처리하지 않는다면 의미가 없는 형태인 것이다. 아무런 조치를 취할 수 없다면, RuntimeException 을 통해 변환하는게 좋을 것이다.
public void aMethod() {
try {
doSomething();
} catch (Exception e) {
}
}
위 코드와 같이 예외를 잡아놓고 아무런 처리를 하지 않는다면 여러 부작용을 낳게 된다. 실제 예외가 발생했더라도 아무런 정보를 얻을 수가 없고, 디버깅하기가 힘들어진다.
public void aMethod() throws ABCException {
try {
doSomething();
} catch(XYZException e) {
throw new ABCException("Error!");
}
}
위의 코드와 같이 상위 계층의 추상화 수준에 맞게 예외를 변환하여 던질려고 하는데, 예외의 원인을 담지 않고 던지고 있다. 결국 상위 계층에서는 이 예외에 대해 충분한 정보를 얻지 못한다.
public void aMethod() throws AnException{
try {
doSomething();
} catch (AnException e) {
log.error("Error", e);
throw e;
}
}
public void bMethod() throws AnException{
try {
aMethod();
} catch (AnException e) {
log.error("Error", e);
throw e;
}
}
public void cMethod() throws AnException{
try {
bMethod();
} catch (AnException e) {
log.error("Error", e);
throw e;
}
}
public void dMethod() throws AnException{
try {
cMethod();
} catch (AnException e) {
log.error("Error", e);
handleException(e);
}
}
위의 코드는 예외를 받는 모든 메소드에서 해당 예외를 잡고 로깅만 하고 다시 던지고 있다. 이렇게 코드를 작성하면 예외가 발생했을 때 로그 정보를 정확하게 분석하기 어려워진다.