

이 글은 http://www.nextree.co.kr/p5864/ 포스트를 보고 study, 정리한 것입니다.
Annotation 이란 사전을 찾아보면 주석 이라는 뜻인데 자바에서 사용하는 주석인 “//”, “/* */” 과는 크게 다르다. 이 annotation 이란 기능은 Java 5부터 등장한 것인데, 우리가 사용하던 주석과는 다르게 설명 그 이상의 행동을 수행한다.
Annotation이 붙은 코드는 annotation이 구현된 정보에 따라 연결되는 방향이 결정된다. 그래서 비즈니스 로직에는 영향이 없지만, 해당 타겟의 연결 방법이나 소스코드의 구조를 변경하는 것이 가능하다. “이 속성을 어떤 용도로 사용할 것인가, 이 클래스에게 어떤 역할을 부여할 것인가” 를 결정해서 붙여준다고 볼 수 있다.
Annotation은 소스코드에 메타데이터를 삽입하는 것이기 때문에 잘만 사용한다면 가독성 뿐만 아니라 체계적인 소스코드를 구성하는데 도움을 줄 수 있다.
@CanSale
public class Apple{
...
}
위의 코드와 같이 annotation은 @ 을 붙여 사용한다. 이 annotation은 자바가 기본적으로 제공하는 것도 있고 (@Deprecated, @Override, @SuppressWarnings), 개발자가 직접 정의해서 사용할 수 도 있다.
개발자는 annotation을 붙일 타겟과 유지시기 등을 결정하여 자신이 원하는 용도로 사용 가능하다. 이 기능을 잘 활용한다면, 비즈니스 로직과는 별도로 시스템 설정과 관련된 부가적인 사항들은 annotation을 통해 위임하고 개발자는 비즈니스 로직 구현에 집중할 수 있다.
이를 이용해 AOP(Aspect Oriented Programming, 관심지향프로그래밍) 을 편리하게 구성할 수 있다. Annotation은 컴파일 시기에 처리할 수도 있고, 자바의 리플렉션 을 통해 런타임 때 처리할 수도 있다.
자바 리플렉션은 실행 중인 자바 클래스의 정보를 볼 수 있게 하고, 그 클래스의 구성 정보로 기능을 수행할 수 있도록 한다. 따라사 자바에서는 리플렉션 기능을 통해 annotation을 더욱 효과적으로 사용할 수 있다.
Annotation을 직접 정의해서 사용해보기 위해서는 먼저 annotation을 정의하는 것이 필요하다. 그 후에 원하는 타겟에 붙여서 사용하는 것이다. Annotation이 붙은 타겟을 어떻게 사용할 지에 대해 구현하면, 해당 기능을 수행될 때 타겟에 붙은 annotation에 따라 타겟의 처리 방향이 결정될 것이다.
다음 문제를 살펴보도록 하자. “다양한 타입의 객체를 단순한 map 저장소에 저장하기 위해, 서로 다른 객체에서 정의된 key 값을 어떻게 식별할까?” 라는 문제이다.
여러가지 방법이 있겠지만, “객체마다 그에 맞는 방법으로 저장”, “인터페이스 상속을 통해 객체의 형태를 통일시켜 일관된 방법으로 데이터 처리”, “annotation을 활용하여 데이터 처리” 이렇게 3가지로 압축할 수 있다.
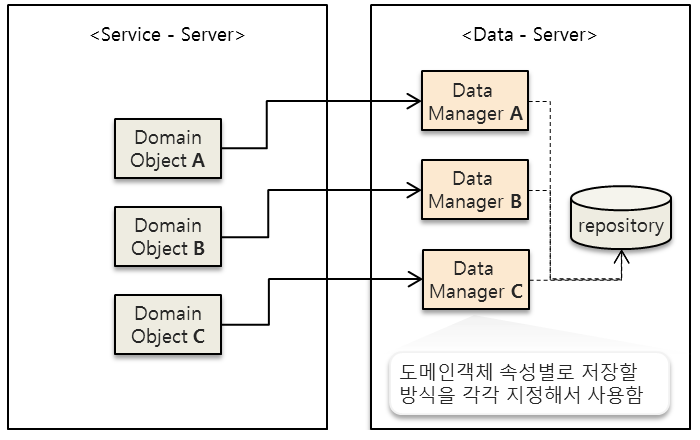
가장 기초적인 방법은 서로 다른 타입의 객체에 대해 맞는 처리 방법을 일일이 지정해리주는 것이다. 그러나 이 방법은 새로운 타입이 늘어날 때마다 그에 맞는 데이터 관리 방법을 일일이 지정해주어야 한다. 또한 위 그림에서의 Data-Server 에서 Service-Server 의 객체의 속성을 알고 있어야 한다는 점에서 좋지 않은 설계라 할 수 있다.
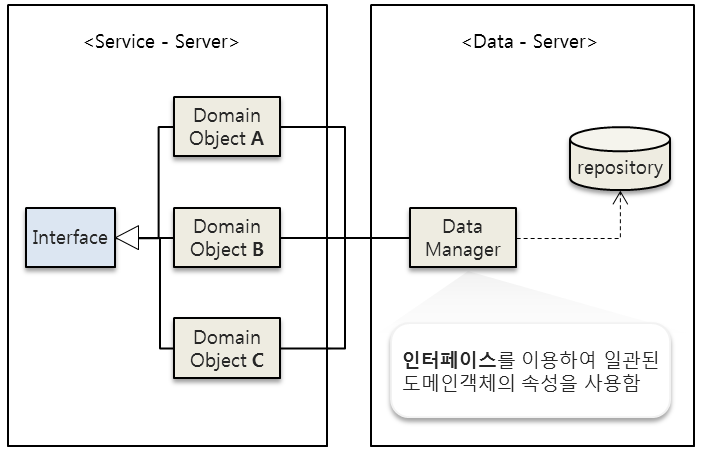
이 방법은 인터페이스 상속을 이용하여 Service-Server 에 있는 모든 객체를 관리하기 위해 특정한 틀을 만드는 것이다. 이러면 Data-Server 에서는 일관된 인터페이스를 통해 속성을 사용할 수 있으므로 객체의 타입이 늘어난다고 해도 Data-Server 쪽의 구현은 한 번만 정의해서 데이터를 관리할 수 있다.
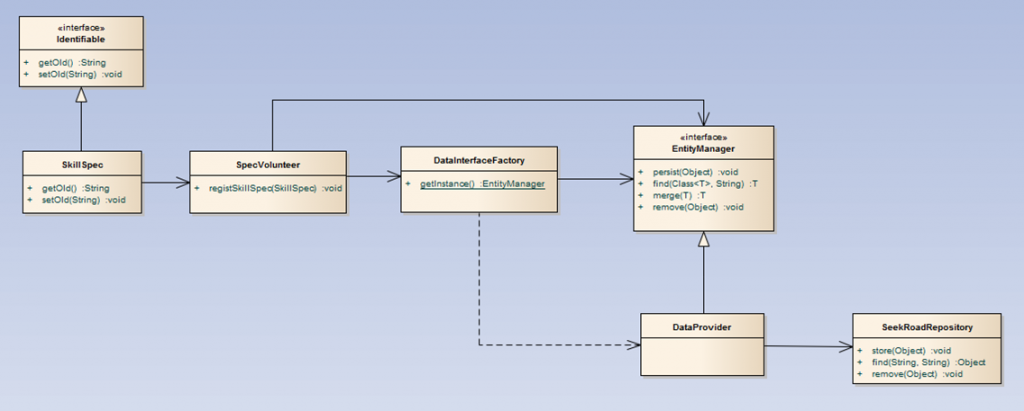
위의 UML에서 객체 SkillSpec 이라는 객체를 저장, 조회, 삭제하는 시스템의 클래스 다이어그램이다. SkillSpec 이 상속받는 Identifiable 인터페이스에는 getOld, setOld 메소드가 있는데 Data-Server 에서는 이 인터페이스를 활용하여 일관된 방법으로 키를 조회할 수 있는 루틴을 구현할 수 있는 것이다. 새로운 타입의 객체를 저장하거나 조회할 때도 이 인터페이스를 상속받으면 Data-Server 의 구현은 수정이 필요가 없어진다.
public interface Identifiable {
//
public String getOId();
public void setOId(String oId);
}
위와 같이 인터페이스를 정의했을 때 다음 코드와 같이 활용하여 데이터를 저장할 수 있다.
public class SeekRoadRepositoryWithoutAnno {
//
private static Map<String,Identifiable> objectMap = new HashMap<String,Identifiable>();
private static SeekRoadRepositoryWithoutAnno repository;
public void store(Identifiable identifiableEntity) {
String className = identifiableEntity.getClass().getName();
if (sequenceMap == null) {
sequenceMap = new HashMap<String,AtomicInteger>();
sequenceMap.put(className, new AtomicInteger(0));
}
AtomicInteger currentSequence = sequenceMap.get(className);
String key = className+ "." + Integer.toString(currentSequence.incrementAndGet());
identifiableEntity.setOId(key);
objectMap.put(key, identifiableEntity);
}
}
어떤 객체라도 Identifiable 라는 인터페이스를 상속할 것이기 때문에 한 번 구현하는 것으로 모든 타입의 객체에 대해 처리할 수 있다.
하지만 이 방법은 모든 객체마다 Identifiable 인터페이스를 상속받아야 한다. 이 객체는 비즈니스 로직 구현 상, 여러 상속관계를 가질 수 있다. 또한 인터페이스를 만들 때 기존의 객체들과 속성이 충돌해서는 안되기 때문에 이를 고려하면서 구현해야 한다. 따라서 이 방법은 개발자 자신이 구현하려는 비즈니스 로직과는 관련없이 데이터 저장 방법을 위해 소스코드에 상속을 추가하고 고려를 해야한다는 점 에서 더 이상 비즈니스 로직에만 집중할 수 없다는 약점이 있다.
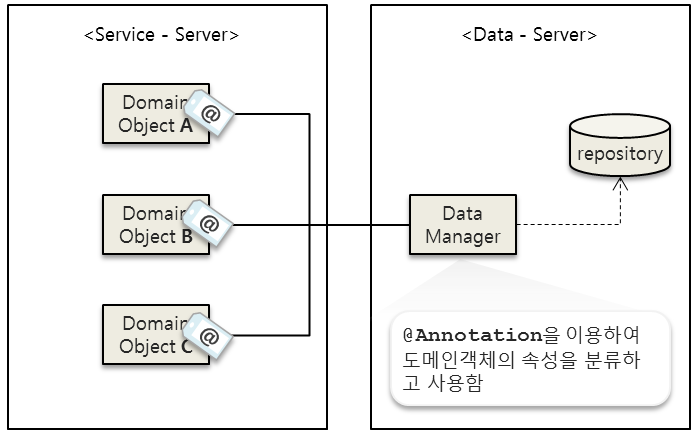
이 방법은 인터페이스를 활용하는 두 번째 방법의 불편함을 해소하는 방법이다. Annotation을 사용하여 똑같은 루틴을 통해 처리할 수 있도록 구현이 가능 하므로, 인터페이스를 상속받지 않더라도 데이터 처리를 할 수 있다.
다음 코드는 데이터 처리를 위한 로직을 구현하기 위해 사용할 annotation의 정의이다.
@Target(ElementType.Field)
@Retention(RetentionPolicy.RUNTIME)
public @interface ObjectId {
}
여기서는 Runtime 때 객체 키 값을 알아내어 데이터 처리를 해야하므로 RetentionPolicy.RUNTIME 으로 설정한다. 다음 코드와 같이 사용할 타겟에 annotation을 적용시킨다.
public class SkillSpec {
@ObjectId
private String oId;
private String name;
private SkillCategory skillCategory;
...
}
위 코드와 같이 oId 필드에 ObjectId annotation을 선언하여 Data-Server 에서 편리하게 이 객체의 key 값을 식별할 수 있도록 한다.
다음으로 annotation을 통해 객체 타입과는 상관잆어 키 값을 읽어올 수 있도록 다음 클래스를 추가한다.
public class ObjectIdAnnotator {
...
public static String getObjectIdValue(Object entity) {
Class<? extends Object> clazz = entity.getClass();
for (Field field : clazz.getDeclaredFields()) {
if (field.getAnnotation(ObjectId.class) != null) {
field.setAccessible(true);
Object value = field.get(entity);
if (value == null) {
return null;
}
else {
return value.toString();
}
}
}
throw new RuntimeException("No annotated id field.");
}
}
위 코드에서 자바 리플렉션을 통해 해당 객체의 타입 정보 및 필드 정보를 얻어오고, field.getAnnotation(ObjectId.class) 구문으로 @ObjectId annotation이 붙은 필드의 값을 String 값으로 리턴하도록 하였다.
그리고 데이터 처리를 위해 다음 코드를 추가한다.
public class SeekRoadRepository {
//
private static Map<String,StoredObject> objectMap = new HashMap<String,StoredObject>();
private static SeekRoadRepository repository;
// ...(생략)
public void store(Object entity) {
//
StoredObject object = new StoredObject(entity);
objectMap.put(object.getId(), object);
}
}
public class StoredObject {
//
private static Map<String,AtomicInteger> sequenceMap;
private String oId;
private String className;
private Object object;
...
public StoredObject(Object entity) {
//
this.className = entity.getClass().getName();
this.oId = nextSequence(this.className);
if (getObjectId(entity) == null) {
ObjectIdAnnotator.setObjectIdField(entity, oId);
}
this.object = entity;
}
...
}
StoredObject 클래스를 통해 클래스 이름과 순번으로 맵에 저장할 객체들에 유일한 시퀀스 넘버를 제공한다. 어떤 객체의 타입이라도 상관없이 ObjectId annotation이 붙어 있는 속성에 키 값을 설정하므로 Map에 저장되는 모든 객체는 유일한 key 값을 가질 수 있다.
이렇게 구현함으로써, 자바 리플렉션 및 annotation을 통해 한 번 구현으로 여러 타입의 데이터를 처리할 수 있는 것이다.
@Target
@Retention
@Documented
@Inherited